factorie-workshop

factorie-workshop
4 7
factorie-workshop
A half-day workshop on FACTORIEOn Github deanwampler / factorie-workshop
FACTORIE Tutorial
FACTORIE
A Scala toolkit for deployable probabilistic modeling.
It provides a succinct language for creating relational factor graphs, estimating parameters, and performing inference.
Dean Wampler
- Consultant at Typesafe
- Big Data and Internet of Things Enthusiast.
- Other expertise: Functional Programming, Scala, Reactive Applications.
Dean Wampler
Goals Today
- Learn about Probabilistic Graphical Models
- Learn about FACTORIE
- Total world domination!!
Navigating the Slides
- Press ESC to enter the slide overview.
- Click the arrows in the lower right corner to navigate.
- Or use the arrow keys.
(Slides written in reveal.js.)
Generating a PDF
Open index.html?print-pdf. Print Profit!What Are Probabilistic Graphical Models? (PGMs)
- Graphical: Represented by nodes and edges.
- Probabilistic: Edges carry probabilities of influence.
- Model: Representation of a real domain.
Bayesian Network
{kind=link}
Probability of Rain or No Rain
- $P(Rain) = 0.20$
- $P(\neg Rain) = 0.80$
- Adds to $1.0$ as it must!
Probability of X Given Y
- $P(Sprinkler|Rain) = 0.01$
- $P(\neg Sprinkler|Rain) = 0.99$
- $P(Sprinkler|\neg Rain) = 0.4$
- $P(\neg Sprinkler|\neg Rain) = 0.6$
Probability of X given Y and Z
- $P(Wet|Sprinkler, Rain) = 0.99$
- $P(\neg Wet|Sprinkler, Rain) = 0.01$
- $P(Wet|\neg Sprinkler, Rain) = 0.80$
- $P(\neg Wet|\neg Sprinkler, Rain) = 0.20$
- $P(Wet|Sprinkler, \neg Rain) = 0.90$
- $P(\neg Wet|Sprinkler, \neg Rain) = 0.10$
- $P(Wet|\neg Sprinkler, \neg Rain) = 0.0$
- $P(\neg Wet|\neg Sprinkler, \neg Rain) = 1.0$
Joint Probability Function
-
Prob. that it is wet, the sprinkler is on and it's raining:
$P(W,S,R) = P(W|S,R)P(S|R)P(R)$
Probability the Grass is Wet?
$P(Wet) = \sum\limits_{s = S,r = R} P(Wet|s, r)P(s|r)P(r)$ $P(Wet) = P(W|\neg S,\neg R)P(\neg S|\neg R)P(\neg R) + $ $P(W|S,\neg R)P(S|\neg R)P(\neg R) + $ $P(W|\neg S,R)P(\neg S|R)P(R) + $ $P(W|S,R)P(S|R)P(R)$ $P(Wet) = 0.0 + 0.9*0.4*0.8 + $ $0.8*0.99*0.2 + 0.99*0.01*0.20$ $P(Wet) = 0.0 + 0.288 + 0.158 + 0.002$ $P(Wet) = 0.448$Prob. the Grass is Wet, No Rain?
$P(Wet|\neg R) = \sum\limits_{s = S} P(Wet|s, \neg R)P(s|\neg R)P(\neg R)$ But, $P(\neg R)$ is now $1.0$: $P(Wet|\neg R) = P(W|\neg S,\neg R)P(\neg S|\neg R) + $ $P(W|S,\neg R)P(S|\neg R)$ $P(Wet|\neg R) = 0.0 + 0.9*0.4$ $P(Wet|\neg R) = 0.360$Uses for Bayesian Networks
- Decision Support Systems
- Medical Diagnosis Decision Trees
- Document Classification
- Information Retrieval
Poor Fits for Bayesian Networks
- Pairwise dependencies that introduce cycles.
- Time-series or other "streams" of data.
Markov Random Field
(a.k.a. Markov Network)
From http://upload.wikimedia.org/wikipedia/en/f/f7/Markov_random_field_example.png
{kind=link}
Markov Random Field
- Undirected dependencies, so cycles allowed.
- Markov Property: Non-adjacent variables are conditionally independent.
Hidden Markov Model
From en.wikipedia.org/wiki/File:SimpleBayesNet.svg{kind=link}
Hidden Markov Model
- Still use the Markov Property
- Time-oriented state changes/transitions.
- Hidden states inferred from observables.
Uses for Hidden Markov Model (1/2)
- Cryptanalysis
- Speech recognition
- Speech synthesis
- Part-of-speech tagging
- Machine translation
Uses for Hidden Markov Model (2/2)
- Gene prediction
- Alignment of bio-sequences
- Protein folding
- Time Series Analysis
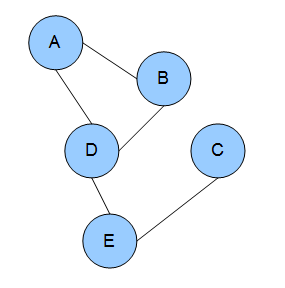
Factor Graphs
From en.wikipedia.org/wiki/File:Factorgraph.jpg{kind=link}
Factor Graphs
- Factored function, i.e., joint probability distribution: $g(X_{1}, X_{2}, ..., X_{n}) = \frac{1}{Z} \prod\limits_{j=1}^{m} f_{j}(S_{j})$
- where
- $S_{j} \subseteq {X_{1}, X_{2}, ..., X_{n}}$
- $Z$ is a normalization constant (we'll assume $Z = 1$)
- Forms a bipartite graph
$g(X_{1}, X_{2}, X_{3}) = f_{1}(X_{1})f_{2}(X_{1},X_{2})f_{3}(X_{1},X_{2})f_{4}(X_{2},X_{3})$
Note that $f_{2}(X_{1},X_{2})f_{3}(X_{1},X_{2})$ form a cycle.
Compute the Marginal of Variable $X_{k}$
The Sum-Product Algorithm: $g_{k}(X_{k}) = \sum\limits_{i=1, i \neq k}^{n} g(X_{1},X_{2},...,X_{n})$ Using our Example: $g_{1}(X_{1}) = f_{1}(X_{1}) \sum\limits_{2,3} f_{2}(X_{1},X_{3})f_{3}(X_{1},X_{2})f_{4}(X_{2},X_{3})$Compute the Marginal of Variable $X_{k}$
Compute $g_{1}(X_{1})$, assume $X_{i}$ are boolean, $i = 1 - 3$: $g_{1}(X_{1}) = f_{1}(X_{1}) \sum\limits_{2,3} f_{2}(X_{1},X_{3})f_{3}(X_{1},X_{2})f_{4}(X_{2},X_{3})$ $g_{1}(X_{1}) = f_{1}(X_{1}) ($ $f_{\neg 2}(X_{1},X_{\neg 3})f_{\neg 3}(X_{1},X_{\neg 2})f_{4}(X_{\neg 2},X_{\neg 3}) + $ $f_{\neg 2}(X_{1},X_{3})f_{3}(X_{1},X_{\neg 2})f_{4}(X_{\neg 2},X_{3}) + $ $f_{2}(X_{1},X_{\neg 3})f_{\neg 3}(X_{1},X_{2})f_{4}(X_{2},X_{\neg 3}) + $ $f_{2}(X_{1},X_{3})f_{3}(X_{1},X_{2})f_{4}(X_{2},X_{3}))$Factor Graphs and
the Sum-Product Algorithm
- Frank R. Kschischang, Brendan J. Frey, Hans-Andrea Loeliger, IEEE Transactions On Information Theory, Vol. 47, No. 2, February 2001.
Factor Graphs
- Unifies directed (e.g., Bayesian) and undirected (e.g., Markov) graphs.
- "Factors" expensive, multivariable function into smaller functions.
- Provides efficient computation of marginal distributions using the sum-product message-passing algorithm (i.e. belief propagation: calculation of the marginal distribution for unobserved nodes, conditioned on observed nodes.)
Bayes Network to Factor Graph
Adapted from Relational Factor Graphs (PPT).
Markov Network to Factor Graph
Adapted from Relational Factor Graphs (PPT).
Factor Graphs for Generative Models?
- But if you need a generative model (where you need to generate data points of any values of $X_{i}$, not marginalize over some of them), Bayesian Networks work best.
Factor Graphs: Examples
- Turbo code - Error correction algos that are so efficient, they enable near-optimal capacity in communication channels.
Relational Factor Graphs
A set of factor templates that can be used to instantiate (directed) factor graphs given data.
See Relational Factor Graphs (PPT).
RFGs Consist of:
- Representation Template:
- Use SQL
- Guarantee no directed cycles
- Inference Template:
- Optimization within a factor.
RFG Example
Adapted from Relational Factor Graphs (PPT).
What is FACTORIE?
About FACTORIE
FACTORIE is a toolkit for deployable probabilistic modeling, implemented as a software library in Scala. It provides its users with a succinct language for creating factor graphs, estimating parameters and performing inference.
FACTORIE "Facts"
FACTORIE "Facts"
- Built-in support for:
- Random variables and factors
- Different learning and inference techniques.
- Scales to billions of variables and factors.
FACTORIE Pre-built Models and Tools
- Classification
- Incl. document classification with MaxEnt, NaiveBayes, SVMs and Decision Trees.
- Linear Regression
- Linear-chain Conditional Random Fields
- Topic Modeling
- e.g., Latent Dirichlet Allocation (LDA).
FACTORIE Pre-built Models and Tools
- Natural Language Processing
- Including pipeline components like tokenization, sentence segmentation, part-of-speech tagging, named entity recognition, dependency parsing, and within-document coreference.
Learning FACTORIE
- Start with the FACTORIE UserGuide - Introduction.
- High-level discussion of concepts.
- Examples using built-in features.
- Includes a detailed list of strengths, weaknesses, and features supported.
- To learn the API, see the FACTORIE Tutorial.
Simple Command-line Examples
- Find Topics Using LDA with Gibbs Sampling, 100 Iterations:
$FACTORIE_HOME/bin/fac lda --read-dirs mytextdir --num-topics 20 --num-iterations 100
- Train a log-linear classifier using maximum likelihood estimation:
$FACTORIE_HOME/bin/fac classify --read-text-dirs dir1 dir2 \ --write-classifier myclassifier.factorie
- (We'll use our own version of fac...)
Detailed Code Sample
package cc.factorie.tutorial
import scala.io.Source
import java.io.File
import cc.factorie._
import app.classify
import cc.factorie.variable.{LabeledCategoricalVariable, BinaryFeatureVectorVariable, CategoricalVectorDomain, CategoricalDomain}
import cc.factorie.app.classify.backend.OnlineLinearMulticlassTrainer
object BookInfoGain {
object DocumentDomain extends CategoricalVectorDomain[String]
class Document(labelString: String, words:Seq[String]) extends BinaryFeatureVectorVariable[String](words) {
def domain = DocumentDomain
var label = new Label(labelString, this)
// Read file, tokenize with word regular expression, and add all matches to this BinaryFeatureVectorVariable
//"\\w+".r.findAllIn(Source.fromFile(file, "ISO-8859-1").mkString).foreach(regexMatch => this += regexMatch.toString)
}
object LabelDomain extends CategoricalDomain[String]
class Label(name: String, val document: Document) extends LabeledCategoricalVariable(name) {
def domain = LabelDomain
}
var useBoostedClassifier = false
def main(args: Array[String]): Unit = {
implicit val random = new scala.util.Random(0)
if (args.length < 2)
throw new Error("Usage: directory_class1 directory_class2 ...\nYou must specify at least two directories containing text files for classification.")
// Read data and create Variables
var docLabels = new collection.mutable.ArrayBuffer[Label]
for (filename <- args) {
val bookFile = new File(filename)
if (!bookFile.exists) throw new IllegalArgumentException("Directory " + filename + " does not exist.")
"\\w+".r.findAllIn(Source.fromFile(bookFile).mkString).toSeq.grouped(500).foreach(words => docLabels += new Document(bookFile.getName, words.filter(!cc.factorie.app.strings.Stopwords.contains(_))).label)
}
val infogains = new classify.InfoGain(docLabels, (l: Label) => l.document)
println(infogains.top(20).mkString(" "))
println()
// val plig = new classify.PerLabelInfoGain(docLabels)
// for (label <- LabelDomain) println(label.category+": "+plig.top(label, 20))
// println()
val pllo = new classify.PerLabelLogOdds(docLabels, (l: Label) => l.document)
for (label <- LabelDomain) println(label.category+": "+pllo.top(label, 40))
println()
// Make a test/train split
val (testSet, trainSet) = docLabels.shuffle.split(0.5)
val trainLabels = new collection.mutable.ArrayBuffer[Label] ++= trainSet
val testLabels = new collection.mutable.ArrayBuffer[Label] ++= testSet
val trainer = new OnlineLinearMulticlassTrainer()
val classifier = trainer.train(trainLabels, trainLabels.map(_.document))
val testTrial = new classify.Trial[Label,Document#Value](classifier, trainLabels.head.domain, _.document.value)
testTrial ++= testLabels
val trainTrial = new classify.Trial[Label,Document#Value](classifier, trainLabels.head.domain, _.document.value)
trainTrial ++= trainLabels
println("Train accuracy = " + trainTrial.accuracy)
println("Test accuracy = " + testTrial.accuracy)
}
}
Learning FACTORIE
- FACTORIE has its own Scala idioms.
- We could get bogged down in the details.
- There is a detailed Tutorial.
Learning FACTORIE
- Instead, let's start with examples from the Users Guide
LDA Example #1 - Shakespeare's plays.
- LDA with Gibbs Sampling, 10 Iterations, *nix command:
exercises/lda shakespeare
- Windows cmd window command:
exercises\lda shakespeare
- It runs this command (*nix version):
bin/fac lda --read-dirs data/shakespeare \ --num-topics 20 --num-iterations 10
LDA Example #1 - Shakespeare's plays.
- You can specify different --num-topics and --num-terations arguments:
exercises/lda shakespeare --num-topics 50 --num-iterations 100
- It runs this command:
bin/fac lda --read-dirs data/shakespeare \ --num-topics 20 --num-iterations 100
LDA Example #2 - Enron Emails
- A large corpus of emails from Enron criminal investigation.
- We'll use a set processed for SPAM classification:
- LDA with Gibbs Sampling, 10 Iterations:
exercises/lda enron
- It runs this command:
bin/fac lda \ --read-dirs "data/enron_spam_ham/ham data/enron_spam_ham/spam" \ --num-topics 20 --num-iterations 10
- Try other values for --num-topics and --num-terations.
Text Classifier
- Train and use a log-linear SPAM classifier using maximum likelihood estimation.
- We'll use the same heavily processed copy of the Enron email dataset from:
Log-linear Classifier
- Train the classifier:
exercises/spam-classifier train
- It runs this long command:
bin/fac classify \ --write-vocabulary data/out/classifier/vocab \ --write-classifier data/out/classifier/enron_email \ --training-portion 0.8 \ --validation-portion 0.2 \ --trainer "new NaiveBayes" \ --read-text-encoding ISO-8859-1 \ --read-text-dirs data/enron_spam_ham/spam data/enron_spam_ham/ham
Log-linear Classifier
- Run the classifier on a some SPAM and HAM emails I received personally:
exercises/spam-classifier classify
- It runs this long command:
bin/fac classify \ --read-vocabulary data/out/classifier/vocab \ --read-classifier data/out/classifier/enron_email \ --write-classifications data/out/classification_results.txt \ --read-text-encoding ISO-8859-1 \ --read-text-dirs data/unclassified
- (There are bugs in this result, at this time...)
Bunch o' Classifier Trainers
- Linear-Vector, Multiclass, and Decision Trees
- Online and Batch
- See src/main/scala/cc/factorie/app/classify in the FACTORIE Git repo.
Linear Vector Classifier (1/4)
-
LinearVectorClassifierTrainer: A "parent class" of other linear-vector classifier trainers:
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
- OnlineOptimizingLinearVectorClassifierTrainer: Pre-tuned with default arguments well-suited to online training, operating on the gradient of one Example at a time.
- ...
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
Linear Vector Classifier (2/4)
-
LinearVectorClassifierTrainer: A "parent class" of other linear-vector classifier trainers:
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
- ...
- BatchOptimizingLinearVectorClassifierTrainer: Pre-tuned with default arguments well-suited to batch training, operating on all the gradients of the Examples together.
- ...
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
Linear Vector Classifier (3/4)
-
LinearVectorClassifierTrainer: A "parent class" of other linear-vector classifier trainers:
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
- ...
- SVMLinearVectorClassifierTrainer: Pre-tuned with default arguments well-suited to training an L2-regularized linear SVM.
-
OptimizingLinearVectorClassifierTrainer: Uses the cc.factorie.optimize package to estimate parameters.
Linear Vector Classifier (4/4)
-
LinearVectorClassifierTrainer: A "parent class" of other linear-vector classifier trainers:
- ...
-
NaiveBayesClassifierTrainer: A LinearVectorClassifierTrainer that, contrary to tradition, does not include a "bias" weight $P(class)$; it only includes the feature weights, $P(feature|class)$.
- What the exercise uses by default.
Multiclass
-
MulticlassClassifierTrainer: Parent class
- BoostingMulticlassTrainer - Works with N other MulticlassClassifierTrainer's.
- OnlineLinearMulticlassTrainer
- RandomForestMulticlassTrainer
- DecisionTreeMulticlassTrainer
- SVMMulticlassTrainer
Decision Trees
-
DecisionTreeClassifier: parent class.
- ID3DecisionTreeClassifier
The FACTORIE API
- Let's do a few exercises to explore the API.
Univariate and MultivariateGaussian Models
- workshop/exercises/ex01/GaussianDemo.scala: Create a model for holding factors connected to 1000 random variables based on samples from a Gaussian. Then use maximum likelihood estimation to re-estimate the mean and variance from the sampled data.
Univariate and MultivariateGaussian Models
- Start sbt:
> run [1] workshop.exercises.ex01.GaussianDemo [2] workshop.exercises.ex01.MultivariateGaussianDemo ... > 1
Univariate and MultivariateGaussian Models
- Invoke run again, select 2.
- Try this variant of run:
> run-main workshop.exercises.ex01.MultivariateGaussianDemo 2
- We passed the argument 2, so it uses a 2-dim. model.
Univariate and MultivariateGaussian Models
... Code Walkthrough ...
Word Segmenter
- workshop/exercises/ex02/WordSegmenterDemo.scala: Train a word segementer based on the observed relations of one character to those that come before and after it, as well as those at the start of a sentence and a word.
Word Segmenter
- Start sbt:
> run [1] workshop.exercises.ex01.GaussianDemo [2] workshop.exercises.ex01.MultivariateGaussianDemo [3] workshop.exercises.ex02.WordSegmenterDemo ... > 3
Word Segmenter
... Code Walkthrough ...
Linear-chain ConditionalRandom Fields
- For parts-of-speech tagging.
- workshop/exercises/ex03/LinearChainCRFDemo.scala: Declare sample data, model, inference and learning for a linear-chain CRF for part-of-speech tagging.
Linear-chain ConditionalRandom Fields
- Start sbt:
> run [1] workshop.exercises.ex01.GaussianDemo [2] workshop.exercises.ex01.MultivariateGaussianDemo [3] workshop.exercises.ex02.WordSegmenterDemo [4] ExampleLinearChainCRFDemo ... > 4
Linear-chain ConditionalRandom Fields
... Code Walkthrough ...
Information Gain(Kullback–Leibler Divergence)
- Build a model that approximates the full set of probabilities for a corpus of texts.
- The "divergence" is a measure of how much the approximate model differs from the actual data.
- workshop/exercises/ex04/BookInfoGain.scala: Read and label a corpus, train a an online classifier, test it.
Information Gain(Kullback–Leibler Divergence)
- Start sbt.
- This time, we'll use two different run-main commands:
> run-main workshop.exercises.ex04.BookInfoGain data/enron_spam_ham/spam100.txt data/enron_spam_ham/ham100.txt > run-main workshop.exercises.ex04.BookInfoGain data/prog_scala/
Information Gain(Kullback–Leibler Divergence)
... Code Walkthrough ...
Conclusions
FACTORIE Pros
- Factor Graphs.
- State of the art belief propagation and other algorithms.
- Excellent performance.
- Scalable to concurrent processing.
FACTORIE Cons
- Too advanced for novice Machine Learning users.
- Spare documentation.
- Non-idiomatic Scala.
Recommendations
- Learn about Factor Graphs (see next slide).
- Learn Scala (because lots of Big Data tools use it).
- If you have basic ML needs, look elsewhere...
- ... but keep FACTORIE in mind!
Resources - Factor Graphs
- Introduction to Factor Graphs (PDF).
- Relational Factor Graphs (PPT).
- IEEE Signal Processing, Jan. 2004 (PDF).
- Factor Graphs and the Sum-Product Algorithm, Frank R. Kschischang, Brendan J. Frey, Hans-Andrea Loeliger, IEEE Transactions On Information Theory, Vol. 47, No. 2, February 2001.
Resources - PGMs
- Machine Learning: a Probabilistic Perspective (Text book).
- Probabilistic Graphical Models (Text book - definitive tome).
Online Courses
- Stanford University: Probabilistic Graphical Models (Coursera).
- Machine Learning and Probabilistic Graphical Models (Univ. of Buffalo).
- Intro. to Artificial Intelligence (Udacity).